Slingshot Yourself Into DataNucleus 2.1 and JPA 2.0
Slingshot Yourself Into DataNucleus 2.1 and JPA 2.0 with this Tutorial for RDBMS
Slingshot Yourself Into DataNucleus 2.1 and JPA 2.0
By Jason Tee & Andy Jefferson (DataNucleus)
comment on this article : ask a question about this example
So, you want to learn DataNucleus AccessPlatform 2.1, and work with the first release of DataNucleus that fully supports JPA 2.0, but you don't want to be led by the nose through any lengthy or long winded tutorials? Well, here it is - the best tutorial you're going to find for getting you started with the DataNucleus AccessPlatform 2.1, and it'll get you started in a hurry.
Get the required JAR files
Nothing happens without JAR files. Get The Required DataNucleus JAR Files. These represent the beautiful, bytecode embodiment of DataNucleus:
Here are the JAR files you're going to need, all of which can be found in the DataNucleus AccessPlatform distribution download:
|
Recommended & Related Reading
Beginning Java Google App Engine
Programming Google App Engine: Build and Run Scalable Web Apps
Pro JPA 2: Mastering the Java™ Persistence API
It's a short list. In fact, it's much shorter than the corresponding list of JAR files you'd need to link to if you were using another JPA provider such as Hibernate.
* By the way, the datanucleus-enhancer.jar and asm.jar are for provision of bytecode enhancement; these JARs are only linked to at compile time, and aren't actually needed at runtime
Downloading the DataNucleus distribution
You will find all of these JAR files in the DataNucleus AccessPlatform 2.1.0 distribution download. Here's where you can download it:
https://sourceforge.net/projects/datanucleus/files/datanucleus-accessplatform/
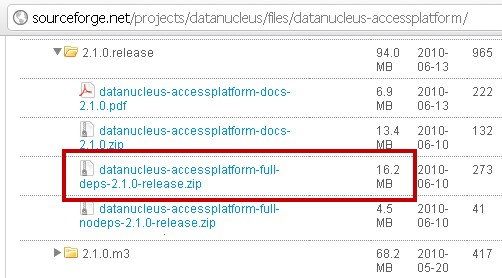
The actual file that was downloaded from this release was named:
datanucleus-accessplatform-full-deps-2.1.0-release.zip
When you download this zip file, the key datanucleus JAR files will be in the "lib" folder of the download. The other JARs will be in the "deps" folder. So, to get working with DataNucleus, you're going to have to move those JAR files out of the downloaded ZIP file, and throw them all into a folder that makes them much more accessible to your Java runtime and design time environments.
Create a folder off the root of your C:\ drive named _dn2.1 and put the required JAR files into it.
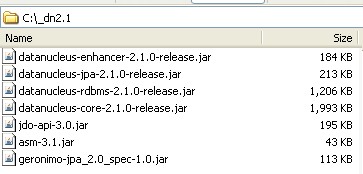
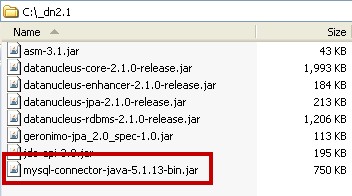
Make Sure You Have Your JDBC Drivers, since this tutorial is for persisting objects to an RDBMS (yes I know that DataNucleus allows persistence to many many other types of datastores, but for now we're going to focus solely on RDBMS).
We're using MySQL for this tutorial, so that means I'm using the mysql-connector-java-5.1.13-bin.jar file, which can be obtained from the Connector/J download page at:
dev.mysql.com/downloads/connector/j/
This JAR file, or whatever JAR file or driver class you use to connect to your database of choice, must be on your Java runtime and design time classpaths. To make life simple, I'm adding this JAR to my C:\_dn2.1 folder as well.
Write some JPA code
DataNucleus AccessPlatform is a persistence framework that saves the state of your Java objects (POJOs) to the database. So, if you want to use DataNucleus, you need to create some POJOs. I'm going to start small, with a GameSummary class that has a single property of type String, representing the results of a single game play, and a property of type Long that will represent the unique identifier the database provides to the instance. Every object to be persisted by a JPA implementation needs some type of identifier that represents its uniqueness, otherwise JPA-based persistence simply won't work. Here's what our JPA annotated GameSummary class looks like:
| package com.mcnz.model; import javax.persistence.*; @Entity @Id private String result; public Long getId() {return id;} public void setId(Long id) { public String getResult() {return result;} public void setResult(String result) { public String toString() { |
The @Entity annotation indicates to the persistence framework that the GameSummary is indeed a persistent class whose state can be managed by DataNucleus. The @Id and @GeneratedValue annotations indicate that the primary key for this class is named id, and is of type Long. Furthermore, the database will be responsible for creating unique ids for new instances that are persisted.
By the way, I simply saved this class in a file named GameSummary.java, in a folder name com\mcnz\model under the C:\_mycode directory. If you're using a crazy IDE like NetBeans or Eclipse, you probably won't need to worry about such things, as the folder structures are created and managed for you. You are responsible however for making sure the required JAR files and the persistence.xml file will be on your runtime and design time classpaths.
The persistence.xml file
When DataNucleus starts persisting entities to the database, it needs to know how to connect to that database, where the database is, and which components are its responsibility for managing. All of that information goes in the persistence.xml file.
| <?xml version="1.0" encoding="UTF-8"?> |
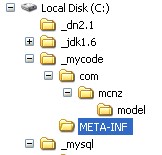 I'm writing all of my code inside of a folder named _mycode, which is right off the root of C:\. The persistence.xml file must reside in a folder named META-INF, which must be on your runtime classpath. Since the _mycode folder will be on my runtime classpath, I'll throw the persistence.xml file into a folder named META-INF right in there.
I'm writing all of my code inside of a folder named _mycode, which is right off the root of C:\. The persistence.xml file must reside in a folder named META-INF, which must be on your runtime classpath. Since the _mycode folder will be on my runtime classpath, I'll throw the persistence.xml file into a folder named META-INF right in there.
Save that file with the name "persistence.xml", and put it on both your runtime and designtime classpath as "META-INF/persistence.xml".
Well, you need a database...
We're going to persist data to an extremely simple database table.
The table will be named gamesummary.
The gamesummary table will have two columns: one primary key column named id of type BIGINT, and another named result of type VARCHAR.
This gamesummary table will be in a schema named rps, which is an abbreviation for "Rock Paper Scissors", which is the greater application we will be building using Spring and JSF, but that will all come later in future tutorials.
You can create your database schema and tables using the MySQL workbench. Here's how you'd visually create a schema using the GUI tools.
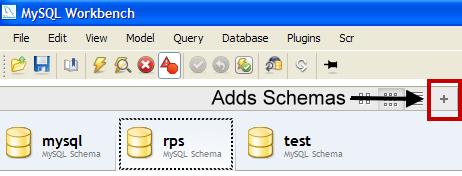
Of course, some people prefer the command line stuff. Our simple database was created by issuing the following SQL DDL commands:
drop table if exists GameSummary
create table GameSummary (id bigint not null auto_increment, result varchar(255), primary key (id))

An even easier way to create your database is to just have DataNucleus do it.
Have DataNucleus create your database tables
DataNucleus provides a "SchemaTool" to generate RDBMS schema for a particular persistence-unit. You can invoke it as follows
C:\>c:\_jdk1.6\bin\java -classpath "C:\_dn2.1\*";C:\_mycode org.datanucleus.store.rdbms.SchemaTool -pu PU
This will create all tables required by the classes being persisted, necessary for JPA persistence. This will typically generate the following SQL
create table GameSummary (id bigint not null auto_increment, result varchar(255), primary key (id))
And you can confirm this by inspecting your "rps" database schema. If all of this happens then you followed these instructions properly, and your DataNucleus environment is up and running! If you do run into any problems here, you might want to do a quick sanity check on your environment, and make sure you've got all of the right JAR files and the persistence.xml file in the right spot. Here's what our current environment looks like:
A File and Sanity Check on the Environment
Here's what your environment should look like, if you've been following along:
|
C:\ ++++ datanucleus-core-2.1.1.jar ++ _mycode\ |
Write some JPA test code
So, does all of this work? Well, that really is the question, isn't it? Code the following class, with a runnable main method, and save it as JpaRunner.java in the com\mcnz\model folder, along with the GameSummary.java file.
| package com.mcnz.model; public class JpaRunner { |
Compile your application
I have my JDK installed to a folder named C:\_jdk1.6; so, to compile this code, and link to the required libraries, I simply run the following command at the DOS prompt:
C:\> c:\_jdk1.6\bin\javac -classpath "C:\_dn2.1\*" C:\_mycode\com\mcnz\model\*.java
Enhancing your model classes
DataNucleus utilizes bytecode enhancement of persistence code so that it can efficiently detect changes to field values. This bytecode enhancement is achieved by simply running the following command:
C:\>c:\_jdk1.6\bin\java -classpath "C:\_dn2.1\*";C:\_mycode org.datanucleus.enhancer.DataNucleusEnhancer -pu PU
The following console output is generated by running the above command:
| July 26 2010 06:06:06 AM org.datanucleus.enhancer.DataNucleusEnhancer <init> DataNucleus Enhancer (version 2.1.0-release) : Enhancement of classes |
And that's it for getting your environment configured and your bytecode enhanced. If you got that to work, you're ready to move on to the next, much easier step, which is actually persisting some data to the database. Here's the command to execute the JpaRunner class:
C:\> c:\_jdk1.6\bin\java -classpath "C:\_dn2.1\\*";C:\_mycode com.mcnz.model.JpaRunner
| July 26th 2010 06:06:06 AM org.datanucleus.ObjectManagerFactoryImpl logConfiguration INFO: Managing Persistence of Class : com.mcnz.model.GameSummary INFO: Creating table `SEQUENCE_TABLE` |
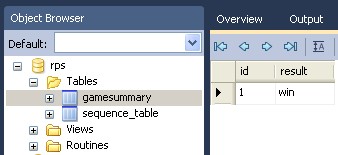
It's interesting to note that along with successfully inserting a new record into the database, DataNucleus quite presumptuously goes into our database and creates an new 'SEQUENCE_TABLE', as can be seen from the MySql Workbench:
And really, that's it. That's how easy it is to get running with DataNucleus and configuring your environment to use DataNucleus as your JPA provider within a stand-alone Java application. And lets face it, if you can get it to work using nothing but a text editor and some command line tools, working with DataNucleus from within a professional, integrated development enviornment, will be a lead-pipe cinch.
comment on this article : ask a question about this example
More about DataNucleus
AccessPlatform : http://www.datanucleus.org/products/accessplatform
Forum : http://forum.datanucleus.org
Issues : http://issues.datanucleus.org
Blog : http://datanucleus.blogspot.com
 Andy Jefferson (United Kingdom)
Andy Jefferson (United Kingdom)
DataNucleus, Project Founder
Andy has over 20 years experience in the IT industry, working as a consultant for many companies in the banking, telecoms, and aerospace sectors as a C, C++ and Java consultant, including UBS, Nomura, Rolls-Royce, Lucent, and GPT Siemens. He has been contributing to Open Source for the last 8 years.
Languages Spoken : English, Spanish
Recommended & Related Reading
Beginning Java Google App Engine
Programming Google App Engine: Build and Run Scalable Web Apps
Pro JPA 2: Mastering the Java™ Persistence API




