
filo/DigitalVision Vectors via G
MySQL vs. PostgreSQL: Compare popular open source databases
This deep dive compares two popular open source database options, MySQL vs. PostgreSQL, across key categories including performance, compliance, security, scalability and more.

MySQL and PostgreSQL are two of the most used open source SQL databases, and both fulfill the role of a general-purpose database well. How do you choose which one to use for a project? Let's look at the relative strengths and weaknesses of each.
About MySQL and Postgres
MySQL was originally open source, but it was bought and taken partially commercial by Oracle in 2010. To ensure it remained a free and independent open source project, the MySQL developers created a fork of MySQL called MariaDB.
MariaDB and MySQL are both mostly backward compatible. Originally they were binary compatible; you could literally drop in MariaDB to replace MySQL with no changes. However, MariaDB offers better performance for some workloads and more storage engines including Aria and ColumnStore.
PostgreSQL, commonly called Postgres, was created by database pioneer Michael Stonebraker and became open source in 1996. It is commonly considered an alternative to proprietary Oracle systems.
Postgres is arguably a more complex and enterprise-ready service, renowned for its effective performance, especially in handling complex queries, large data sets and concurrent connections. But let's take a closer look at MySQL and Postgres across several important database categories: performance; SQL compliance; complex queries and data handling; replication; scalability and security.
Performance
Database performance encompasses many factors, such as query optimization, configuration, indexing and caching.
MySQL
Beyond those factors, one of MySQL's main selling points is the ability to use different storage engines, and it is important to choose the correct one. There are three main options:
- InnoDB. The default engine, this offers transactions, high performance on data integrity and row locking.
- MyISAM. An older engine, it is very fast for read operations but lacks data transactions, and write speeds are inferior to InnoDB.
- In-memory. Stores all the data in RAM, with very fast performance; mainly used for temporary tables.
The default storage engine, InnoDB, is ideal to handle workloads with emphasis on data integrity and speed, such as fast lookups on referential integrity. Read performance is also very good with this engine, tuned with some commonly used methods standard to most SQL servers and others unique to MySQL, including the following:
- Indexing. The addition of indexes to columns speeds up data retrieval, for example, B-trees.
- Caching. Query caching and TTL expiry and cache eviction reduce the execution time and reduce the number of calls to the underlying persistence model.
- Partitioning. Dividing large tables into smaller chunks speeds up querying.
- Read replication. Similar to a load balancer for SQL, read requests can be offloaded to replicas to enhance performance under heavy read traffic.
PostgreSQL
Performance in PostgreSQL is influenced by various factors, most notably the following:
- Query optimization. Postgres supports indexing, but it also augments this with execution strategies such as EXPLAIN and ANALYZE to enable on-the-fly query optimizations.
- Configuration tuning. This enables the ability to tune workloads based on the system hardware, the use of shared buffers and effective cache sizing.
- Concurrency. PostgreSQL uses multiversion concurrency control (MVCC) to ensure consistent data handling without locking issues, which provides excellent performance in highly concurrent environments. MySQL has similar implementations to MVCC, but Postgres' MVCC implementation is much more aggressive.
- Parallelism. PostgreSQL supports parallel query execution, where certain queries can be split across multiple CPU cores for faster processing.
PostgreSQL excels at handling complex queries. It has many unique data types and queries to support processing of huge data sets, such as the following:
- Window functions. This powerful tool enables complex data analysis tasks, such as running totals and moving averages so users can offload some analytics from the code to the DB engine.
- Common table expressions (CTEs). PostgreSQL provides recursive and nonrecursive CTEs, which help break down large queries into more manageable components. This happens automatically inside the query execution layer.
- Full-text search. PostgreSQL natively supports full-text search capabilities, which enables complex search functionalities so users can offload text searching directly into the DB engine.
- JSON and JSONB. PostgreSQL supports the ability to store and query JSON data, so it is suitable for hybrid applications that require structured and semistructured data querying.
Where PostgreSQL really excels in performance, and which MySQL doesn't handle as well, is in write-heavy applications. PostgreSQL writing is optimized through several features:
- Buffering and caching. PostgreSQL uses internal buffers and caching mechanisms to optimize write performance.
- Batch processing. For high write throughput, PostgreSQL supports batching inserts and updates, which can lead to huge performance gains when dealing with large volumes of data.
- Concurrency control. MVCC ensures simultaneous multiple writes without conflicts, which reduces contention and improves throughput in multitenant environments.
Compliance
MySQL and PostgreSQL both support the SQL standard, as well as various other features.
MySQL
MySQL supports the SQL:2003 standard, and includes features such as stored procedures, triggers and views. It offers a range of standard data types, including INT, VARCHAR, DATE, CHAR and FLOAT, and supports specialized data types such as ENUM and SET, which allow for predefined lists of values.
PostgreSQL
Postgres is fully compliant with SQL:2011, and adds in many custom data types. It offers extensive support for ANSI SQL features as well as some custom extensions such as array support, custom data types and advanced indexing mechanisms.
Postgres also ensures data integrity with features such as CHECK constraints, domain constraints and exclusion constraints that are often more advanced than other SQL databases.
Replication
Replication is one area of comparison where MySQL and Postgres diverge in their approach.
MySQL
Replication in MySQL is simple to set up and is very flexible. It can be configured in different topologies depending on the specific needs of the system, such as primary-replica (one primary, multiple replicas), primary-primary (two servers act as both primary and replica), or multisource (a single replica server collects data from multiple primaries).
MySQL uses three main replication modes:
- Asynchronous replication. The main server writes changes to binary entries and they are sent to the replicated servers. This offers a delta-like replication and is fully async; however, it can have delays between replicas.
- Semisynchronous replication. This waits for at least one replica to acknowledge the replication of the changes before the transaction is completed.
- Group replication. This fully fault-tolerant and highly available multi-primary replication service enables MySQL to distribute data across multiple servers, which improves availability and performance, especially in read-heavy environments.
PostgreSQL
Replication in PostgreSQL is more complex and more difficult to set up than MySQL, but it is also more flexible and robust. Postgres offers various replication options to enhance scalability and fault tolerance, such as the following:
- Streaming replication. PostgreSQL supports asynchronous streaming replication, where changes from the primary node are continuously shipped to replica nodes. This is similar to MySQL asynchronous replication.
- Synchronous replication. With this, a transaction is considered committed only after it has been written to both the primary and replica nodes. This is similar to MySQL's semisynchronous replication, except that it ensures the transaction is complete when both the primary and the replica nodes have the data.
- Logical replication. Logical replication lets data be replicated at a more granular level, such as specific tables or sets of data, rather than entire databases.
- Hot standby. PostgreSQL enables read queries to be executed on replica nodes in hot standby mode, which helps distribute the load while maintaining high availability.
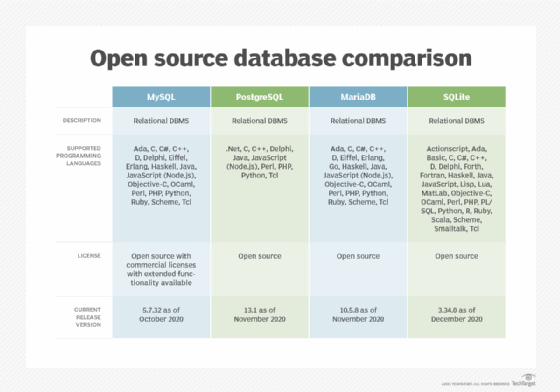
![Comparison of open source relational databases: MySQL, PostgreSQL, MariaDB and SQLite.]()
How MySQL and PostgreSQL line up for language support and licensing and compare with other open source relational databases.
Security
Both MySQL and PostgreSQL offer an array of security features, from authentication to encryption to logging and auditing.
MySQL
Security in MySQL is robust and easy to set up. It provides effective user authentication mechanisms and strong encryption features, such as the following:
- Authentication. Supports a robust authentication mechanism, including native password encryption and integration with LDAP and PAM.
- Roles and privileges. Users have role-based access to tables and models, which enables find-grained access over databases and operations.
- Encryption. MySQL supports SSL/TLS to secure connections and data-at-rest encryption to secure sensitive data.
- Audit logs. To monitor user activity and ensure compliance with security policies.
PostgreSQL
Postgres likewise has a wide range of security features, including the following:
- Authentication. PostgreSQL supports various authentication methods including password-based methods (e.g., MD5 and SCRAM-SHA-256), Kerberos, GSSAPI, LDAP and certificate-based authentication.
- Role-based access control. Like MySQL, Postgres also uses roles for managing access and permissions.
- Data encryption. Like MySQL, PostgreSQL supports SSL/TLS encryption. For data at rest, PostgreSQL doesn't natively support transparent data encryption, but application-level solutions or disk-level encryption can be implemented.
- Row-level security. With RLS, you can define policies that control access to specific rows within a table, providing fine-grained access control for multitenant or highly sensitive applications.
- Auditing. PostgreSQL supports logging and auditing via extensions, which can track and log all database activities, helping with monitoring and security compliance.
Verdict: Different databases for different needs
Both MySQL and PostgreSQL are powerful open source relational databases, but they excel in different areas, which makes each more suitable for specific use cases.
Performance
MySQL is known for its speed, especially in read-heavy workloads and simple queries. PostgreSQL, while slightly slower in basic operations, excels in write-heavy workloads and complex queries thanks to advanced features including MVCC, parallel query execution and indexing options.
SQL compliance
PostgreSQL is highly SQL-compliant, supporting advanced features including window functions, CTEs, and complex data types. This makes it ideal for systems that require complex queries and adherence to SQL standards. MySQL, while compliant, tends to be more flexible but sacrifices some strictness for performance.
Complex queries and data handling
PostgreSQL shines in handling complex queries and data analysis. It's the go-to for use cases involving advanced analytics or scientific applications that need complex calculations. MySQL, while capable of complex queries, is generally preferred for web applications where fast, simple queries dominate.
Replication and scalability
Both databases offer robust replication options, but MySQL has an edge with tools for multimaster replication in high-availability systems.
Security
PostgreSQL provides more advanced security features, such as row-level security and auditing, making it suitable for use cases requiring fine-grained access control, such as multi-tenant applications or sensitive data handling.
Overall, MySQL is often used for web and transactional applications due to its simplicity and performance, while PostgreSQL is preferred for data-intensive, analytical or high-integrity systems that demand advanced SQL features and security.
David "Walker" Aldridge is a programmer with 40 years of experience in multiple languages and remote programming. He is also an experienced systems admin and infosec blue team member with interest in retrocomputing.






