How to write a screen scraper application with HtmlUnit

I recently published an article on screen scraping with Java, and a few Twitter followers pondered why I used JSoup instead of the popular, browser-less web testing framework HtmlUnit. I didn’t have a specific reason, so I decided to reproduce the exact same screen scraper application tutorial with HtmlUnit instead of JSoup.
The original tutorial simply pulled a few pieces of information from the GitHub interview questions article I wrote. It pulled the page title, the author name and a list of all the links on the page. This tutorial will do the exact same thing, just differently.
HtmlUnit Maven POM entries
The first step to use HtmlUnit is to create a Maven-based project and add the appropriate GAV to the dependencies section of the POM file. Here’s an example of a complete Maven POM file with the HtmlUnit GAV included in the dependencies.
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.mcnz.screen.scraper</groupId>
<artifactId>java-screen-scraper</artifactId>
<version>1.0</version>
<dependencies>
<dependency>
<groupId>net.sourceforge.htmlunit</groupId>
<artifactId>htmlunit</artifactId>
<version>2.34.1</version>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<artifactId>maven-compiler-plugin</artifactId>
<configuration>
<source>1.8</source>
<target>1.8</target>
</configuration>
</plugin>
</plugins>
</build>
</project>
The HtmlUnit screen scraper code
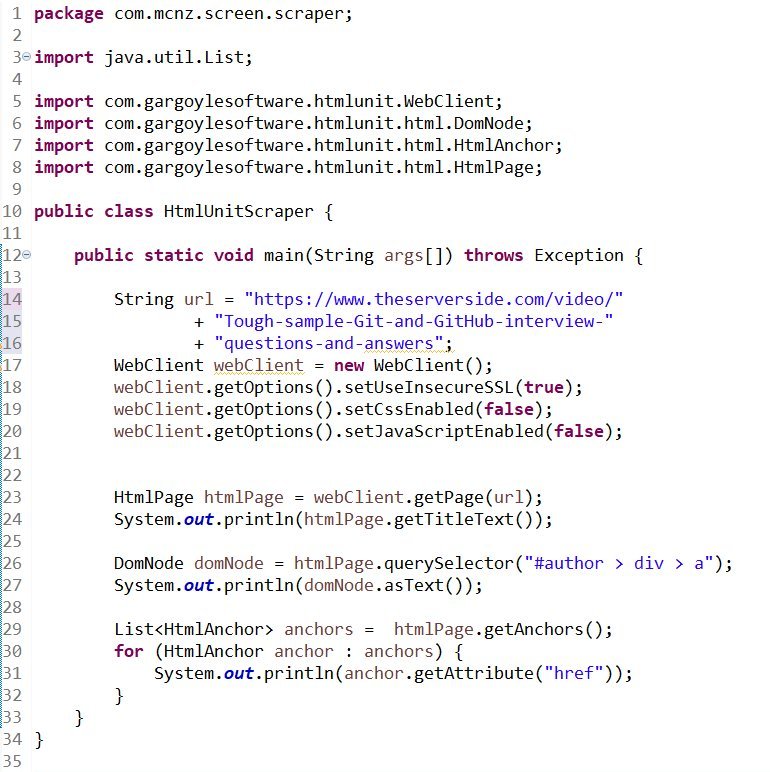
The next step in the HtmlUnit screen scraper application creation process is to produce a Java class with a main method, and then create an instance of the HtmlUnit WebClient with the URL of the site you want HtmlUnit to scrape.
package com.mcnz.screen.scraper;
import com.gargoylesoftware.htmlunit.*;
import com.gargoylesoftware.htmlunit.html.*;
public class HtmlUnitScraper {
public static void main(String args[]) throws Exception {
String url = "http://www.theserverside.com/video/IBM-Watson-Content-Hub-has-problems-before-you-even-start";
WebClient webClient = new WebClient();
webClient.getOptions().setUseInsecureSSL(true);
webClient.getOptions().setCssEnabled(false);
webClient.getOptions().setJavaScriptEnabled(false);
}
}
The HtmlUnit API
The getPage(URL) method of the WebClient class will parse the provided URL and return a HtmlPage object that represents the web page. However, CSS, JavaScript and a lack of a properly configured SSL keystore can cause the getPage(URL) method to fail. It’s prudent when you prototype to turn these three features off before you obtain the HtmlPage object.
webClient.getOptions().setUseInsecureSSL(true); webClient.getOptions().setCssEnabled(false); webClient.getOptions().setJavaScriptEnabled(false); HtmlPage htmlPage = webClient.getPage(url);
In the previous example, we tested our Java screen scraper capabilities by capturing the title of the web page being parsed. To do that with the HtmlUnit screen scraper, we simply invoke the getTitle() method on the htmlPage instance:
System.out.println(htmlPage.getTitleText());
Run the Java screen scraper application
You can compile the code and run the application at this point and it will output the title of the page:
Tough sample GitHub interview questions and answers for job candidates
The CSS selector for the segment of the page that displays the author’s name is #author > div > a. If you insert this CSS selector into the querySelector(String) method, it will return a DomNode instance which can be used to inspect the result of the CSS selection. Simply asking for the domNode asText will return the name of the article’s author:
DomNode domNode = htmlPage.querySelector("#author > div > a");
System.out.println(domNode.asText());
The last significant achievement of the original article was to print out the text of every anchor link on the page. To achieve this with the HtmlUnit Java screen scraper, call the getAnchors method of the HtmlPage instance. This returns a list of HtmlAnchor instances. We can then iterate through the list and output the URLs associated with the links by calling the getAttribute method:
List<HtmlAnchor> anchors = htmlPage.getAnchors();
for (HtmlAnchor anchor : anchors) {
System.out.println(anchor.getAttribute("href"));
}
When the class runs, the following is the output:
Java screen scraper with HtmlUnit
Tough sample GitHub interview questions and answers for job candidates.
Cameron McKenzie.
Link: https://www.theserverside.com/video/Tips-and-tricks-on-how-to-use-Jenkins-Git-Plugin
Link: https://www.theserverside.com/video/Tackle-these-10-sample-DevOps-interview-questions-and-answers
Link: https://www.theserverside.com/video/A-RESTful-APIs-tutorial-Learn-key-web-service-design-principles
JSoup vs HtmlUnit as a screen scraper
So what do I think about the two separate approaches? Well, if I was to write a Java screen scraper of my own, I’d likely choose HtmlUnit. There are a number of utility methods built into the API, such as the getAnchors() method of the HtmlPage, that makes performing common tasks easier. The API is updated regularly by its maintainers, and many developers already know how to use the API because it’s commonly used as a unit testing framework for Java web apps. Finally, HtmlUnit has some advanced features for processing CSS and JavaScript which allows for a variety of peripheral applications of the technology.
Overall, both APIs are excellent choices to implement a Java screen scraper. You really can’t go wrong with either one.
You can find the complete code for the HtmlUnit screen scraper application on GitHub.
HtmlUnit screen scraper application