
kentoh - Fotolia
Your near-zero downtime microservices migration pattern
The possibility of extended downtime is a common reason to avoid a migration to microservices. Learn how to minimize downtime with this monolith-to-microservices migration pattern.

The transition from monoliths to microservices isn't easy. One of the big challenges solution architects must address is how to move existing systems into a microservices-oriented architecture without triggering extensive downtime and violating service-level agreements, or SLAs. The zero-downtime microservices migration pattern is designed to address this very issue.
One of the key tenets of microservices design is process isolation. In monolithic systems, many workflows and processes will share data stored in a common database or NoSQL store. This isn't a best practice for microservices. The ideal microservices-oriented application is one in which each microservice carries its own data in an isolated manner.
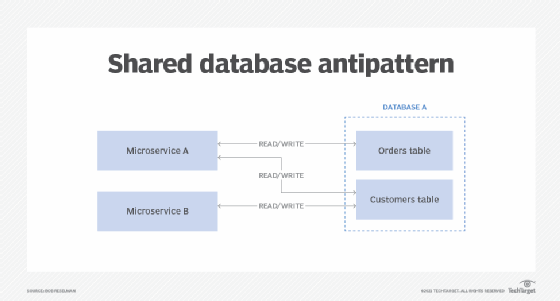
Figure 1 provides a visual representation of this microservices anti-pattern. As you can see, both Microservice A and Microservice B share a common database that contains the tables named Orders and Customers. Only Microservice A writes to the Orders table, but both write to Customers.
Microservices transition challenges
The anti-pattern in Figure 1 is common to monolithic applications. The difficulty development teams have when they transition away from this configuration is twofold:
- How do you design the product so data access is isolated?
- How do you transition from monolith to microservices with minimal downtime?
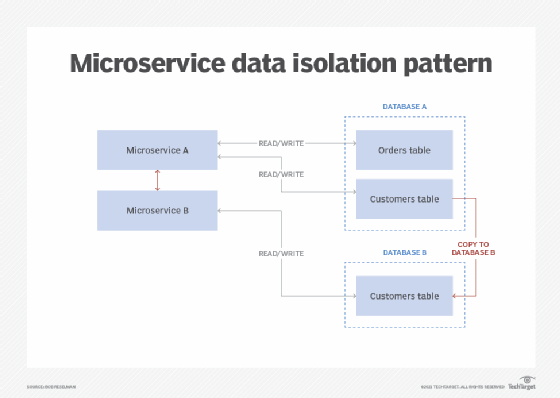
The easiest way to address the data isolation anti-pattern is to give Microservice B its own copy of the Customers table. Unfortunately, having a database admin simply do a clone of the Customers table isn't good enough.
Both Microservice A and Microservice B need to be analyzed by the architect to determine whether the given microservice is using customer data in a way that is particular to the context of the other service. For example, does Microservice A rely upon Customer data that has been changed by Microservice B in a particular way?
You need to analyze how the data is used first because the results will affect how the migration from monolith to microservice occurs. If the microservices access the underlying database in a dependent manner, this aspect of the code will need to be refactored.
To establish microservices data isolation:
- Shut down system.
- Move copy of Customers table to Database B.
- Redirect Microservice B to read/write Customers table from Database B.
- Rewrite Microservice A to read/write Customers data using Microservice B.
SLA-friendly microservices migration patterns
With the microservices refactored to access data in an isolated manner, the next challenge is to transition to the isolated architecture with minimal downtime. Follow these steps to accomplish a minimal downtime transition:
- Take Microservice A and Microservice B offline.
- Create a new database named Database B.
- Copy the data from the Customers table from the old database to the new one.
- Deploy the two refactored microservices to end the downtime.
When the process is complete, the new code for Microservice A and Microservice B are completely independent of each other in terms of process boundary and data access.
Zero downtime challenges
The approach above will suffice if the company building the microservices-oriented architecture has the luxury of incurring a small amount of downtime to do the revision. This will be the case if the data structures are not complex and data sets are not excessively large. For many organizations, the size of the database to migrate may act as a limit to the applicability of this monolith-to-microservices migration pattern.
If the situation is one in which tens of millions of users rely upon the shared data and the data is changed at the granularity of milliseconds or even nanoseconds, then any downtime of more than a millisecond will be unacceptable. In these situations, the refactoring needs to incur no downtime of the application at all. Data sets on the order of terabytes and petabytes can take hours to copy, with the network bandwidth also playing a key part in the data copy speed.







