The Pragmatic Code Generator Programmer
In this article we will reimplement an exercise taken from the best-selling book "The Pragmatic Programmer" written by Andy Hunt and Dave Thomas [1]. In the third chapter "The Basic Tools" the authors motivate the reader to learn a "text manipulation language" (like Perl or Ruby) in order to be able to develop little code generators.
In this article we will reimplement an exercise taken from the best-selling book "The Pragmatic Programmer" written by Andy Hunt and Dave Thomas [1]. In the third chapter "The Basic Tools" the authors motivate the reader to learn a "text manipulation language" (like Perl or Ruby) in order to be able to develop little code generators. The proposed exercise is very simple and code-centric and we will show how it can be implemented with today's generator development tools and languages.
The definition and use of custom languages (also called domain-specific languages, or DSLs), used in conjunction with suitable code generators, is a very useful practice in day-to-day development. It provides ways to work with exactly those abstractions you need in the respective context. A good code generator basically works like a compiler: It reads some input, creates an intermediate representation called an abstract syntax tree (AST), validates the AST for structural correctness, performs various modifications (linking, etc.) and optimizations on it before eventually some other representation is created (typically code in some target language). In the world of Model Driven Software Development (MDSD) [2] such an AST is called a model; the elements the model is made of (i.e. the types of the AST objects) are called a meta model. A "program" written in a DSL is often called a specification or a model, too. In the rest of this article we will use these terms instead of those from compiler construction.
openArchitectureWare[3] is an Open Source project that provides tools to develop code generators; simple ones like the one required for this exercise, as well as more powerful ones, integrated in the IDE using multiple input languages interconnected with each other. In this article we will show that although openArchitectureWare is a powerful framework with lots of advanced features for developing leading edge generators, we can implement the simple exercise from the Pragmatic Programmer book in a straight forward and more maintainable way by using the technology proposed by the pragmatic programmers, namely Perl.
The exercise
"Write a code generator that takes the input in Listing 1, and generates output in two languages of your choice. Try to make it easy to add new languages."
Listing 1
# Add a product # to the 'on-order' list M AddProduct F id int F name char[30] F order_code int E
The exercise doesn't show the real power of defining domain-specific languages and subsequent code generation, because it just abstracts from the target language instead of adding real conceptual abstractions. MDA-afficionados may like this view since MDA mainly focuses on abstracting from the target platform to gain platform independence. In our experience, platform independence is in most cases not really the most important reason for using MDSD.
So, before we start implementing the exercise with openArchitectureWare, let's have a short look at the book's proposed solution:
"We use Perl to implement our solution. It dynamically loads a module to generate the requested language, so adding new languages is easy. The main routine loads the back end (based on a comment-line parameter), then reads its input and calls code generation routines based on the content of each line. We're not particularly fussy about error handling - we'll get to know pretty quickly if things go wrong."
Listing 1

The code may look very simple at first glance (as long as the language to be parsed is simple and you are used to working with regular expressions). However, Perl is not specifically designed to implement parsers. Consequently, the program does not reveal the structure of the to-be-parsed language directly; it is "hidden" in the program. Wouldn't it be better to describe the syntax of the language declaratively, using a language that is custom-made for describing the syntax of other languages? So, let's try.
Generating a parser
We will use the grammar language provided by xText, a framework that supports the efficient development of textual DSLs. Supplied with a language description, xText can generate
- a meta model that represents the abstract syntax of the described language
- a parser that reads the concrete syntax of a given "model" in the DSL and instantiates an AST
- as well as an Eclipse editor plug-in that makes editing "models" more convenient
The following screen shot shows how the syntax is described for the DSL shown in the exercise above. We use a screen shot because we want to illustrate that xText also offers tool support for it's grammar language. In fact language and tooling used for describing DSL syntax is bootstrapped, i.e. it is implemented using the xText framework itself. Bootstrapping is a common technique in the field of language and compiler development. If you can bootstrap your language and tools, this proves a certain level of maturity of the tools.
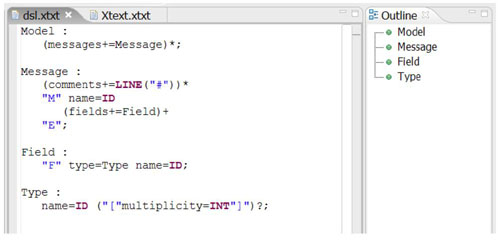
What's in a grammar?
An xText grammar consists of a number of rules (Model, Message, Field and Type). A rule is described using sequences of tokens. A token is either a reference to another rule or one of the built- in tokens (STRING, ID, LINE, INT). xText automatically derives the meta model from the grammar (remember that the meta model is basically a data structure whose instances represent the structure of sentences in the language). A rule results in a meta type, the tokens used in the rule are mapped to properties of that type (comments, name, fields). There are different assignment operators used in our example. The equals sign ('=') just assigns the value returned from the token to the respective property (the property will have the type of the token) and '+=' adds the value to the property (the property will have the type List<tokenType>).
The first rule in the file (Model) is called the entry rule. It acts as a container for all the Messages contained in our input. The property that holds the list of messages is called messages. A Message starts with any number (note the quantifier '*') of comments, while each comment in turn starts with a hash '#' and ends with the end of the current line. This is described with the built-in token type LINE(startpattern). Each comment is added (hence the use of +=) to the comments property of the current Message. The message's body starts with the keyword "M" (nice keyword, isn't it? ;-)) followed by an ID which acts as the name of the message.
An ID is also a built-in token, which must correspond to the regular expression '[azAZ_]+[azAZ_09]*', which means that it is basically a sequence of characters and digits, as well as the underscore. Additionally it must not be a keyword, so 'M' and 'F' are not allowed as a message's name (note that this is automatically enforced by xText).
A Message contains at least one (quantifier '+') field, each Field starting with the keyword 'F' followed by a type (described in it's own rule) and the field's name.
A Type can either be a simple type, or optionally (quantifier '?') an array. If this is the case the property multiplicity will be set to the specified number.
What do we get?
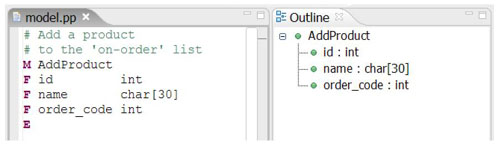
So we have described the DSL with a few lines of code. And, yes, that's all! In contrast to the Perl solution we do not have a simple event-driven parser, but a DOM-like parser that creates an actual AST (an object graph in memory) for our model. In addition, the xText tooling has generated a textual editor plug-in for Eclipse, which offers features such as syntax highlighting, an outline view and real time validation. Let's have a look at it.
Static checking
The Perl solution from the book doesn't have any support for validating models written in our DSL. So errors won't be found until the parser runs, or even worse, when the data is used in some way. However, what we really want is that the program is checked for syntactically and semantic correctness before it is processed any further, because it makes no sense to process an invalid program. It would also be really helpful if we could get feedback about invalid models/programs while editing them - just as we're used to when editing e.g Java code. openArchitectureWare comes with a language called Check which is specialized for model validation. Check is very similar to OCL[4], but uses oAW's expressions sub-language. If you want the parser and editor generated by xText to validate your models, all you have to do is add the respective constraints to a Check file.
Here it is:
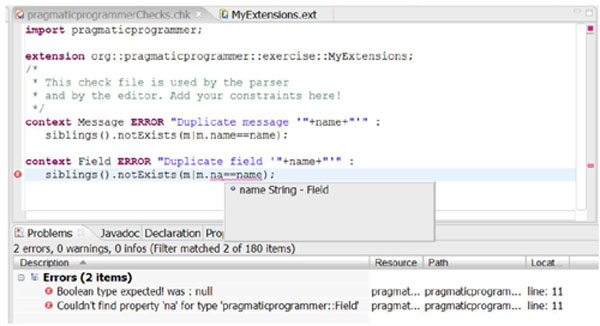
The screen shot also shows the tool support for the Check language. As Check is statically typed, the editor supports static type checking as well as code completion proposals. But let's talk about the language itself. Basically a check file consists of a number of constraints. A constraint starts with the keyword context followed by the name of the type for which this constraint must hold.
The severity is expressed using one of the keywords ERROR or WARNING. The message (e.g. "Duplicate message '"+name+"'") can be any valid expression as long as it returns a String. The constraint expression itself is defined after the colon. This expression must evaluate to a boolean. All constraints must be true in order for the complete model to be valid. Finally, each constrain is terminated by a semicolon. There is an implicit this variable pointing to the current element to be checked. As in OO programming, the this can be omitted, so we can just write name instead of this.name to access the name property of the element.
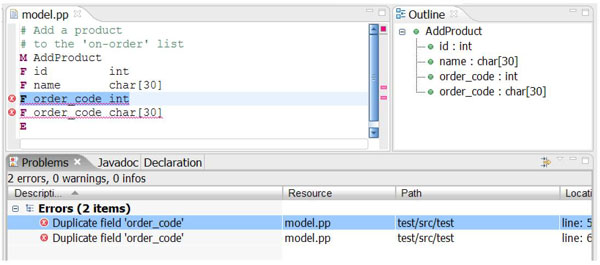
The first constraint makes sure that the name of each message is unique within the model (in our case, the text file). There is an extension (more about extensions in a minute) returning all siblings of the current message. We then ensure that messages have unique names by checking whether there is a message with the same name among its siblings. The way we do this is by invoking notExists(m|m.name==name) on the list of siblings. notExists is one of several higher-order functions for collections, it takes a predicate and evaluates it for each element of the list. The current element is temporarily bound to the local variable m. notExists returns true, if the predicate returns false for each of the elements it iterates over. Here is a screen shot of our generated editor having found constraint violations:
Extensions
Extensions are used to add behaviour, derived properties or other aspects to your meta types without touching the original definition of the meta type. They are defined using the xTend language which is a powerful functional language also based on oAW's expressions language. xTend also has features for model-to-model transformations, but since we don't need them here we won't explain them.
To be able to use extensions in constraints, you have to import the extension file that defines the required extensions into the Checks file. This is done using the extension keyword. The extensions used in our checks look as follows:
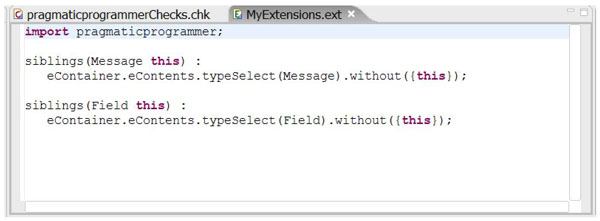
The siblings extension simply selects all the children (eContents) of the current element's parent (eContainer). From that list, we remove the element on which we've called the siblings function - we only want the element's siblings, not the element itself. Removing elements from a set is done using the without operation, the expression {this} creates a list containing just one element: this.
Generating Code
So far we have developed a parser and a specialized editor for the pragmatic programmers DSL in about 22 lines of code. In the next part of this article we will show how to implement a generator backend. Let's first have a look at how the pragmatic programmers have done it in their book.
Listing 2

Remember that the parser developed in the first part of the exercise has used an event-driven approach. Hence, the generator backend needs to adhere to this approach; so it basically provides callback operations for each of the events that can occur from the parser. This is certainly not the best solution, because it's very hard to get an idea of what kind of output the generator will produce. Have you ever implemented a SAX handler for a complex XML language? It's definitely not that much fun.
Back to the openArchitectureWare solution. Since our parser creates an object graph representation of our model (the abstract syntax tree), our generator is not written against events but against meta types from which the AST is built. To generate the actual code, we use xPand, a template language also based on openArchitectureWare's expression language. Therefore you can use the meta model, expressions and extensions we have seen in the previous section. Here are the templates:
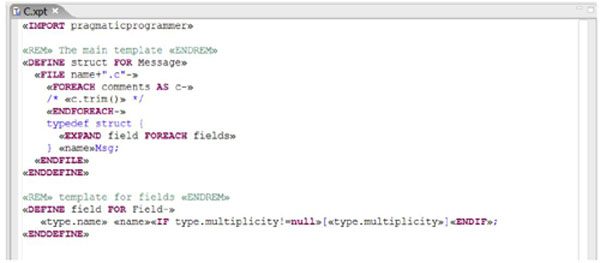
An xPand template file consists of one or more templates declared using the DEFINE keyword. A template has a name (such as struct) and is bound to a specific meta type (for example, Message). This binding is important, since, whenever you execute the template, there's an implicit this variable that points to an instance of that meta type, the element, for which the template is currently executed. Inside the main template struct there is a FILE block which opens a file with the specified name (name+".c"). All the text that is generated inside that FILE...ENDFILE block is written to that file. The usual control structures such as FOREACH and IF are available. You can call other templates using the EXPAND statement, passing the context element along (an instance of the type for which the target template is defined).
The generator description is not necessarily shorter, but it's much more readable because you can see what the resulted code actually will look like. In real life, code generators are often more complex than this one so I really don't want to see complex ones written in Perl the way the authors suggest. Note, that again we have rich tool support (static checking, code completion, etc.) for xPand templates.
Binding things together
In order to run the example, we need to define a process that
- first invokes the generated parser to instantiate an AST from our model (text file)
- and then passes that AST to the xPand engine in order to generate the target code.
Again, oAW offers a specialized tool for that purpose: the workflow engine. Generator workflows are described in XML. The language is actually a mixture of the Spring configuration language and ant. This is how our workflow looks like:
Listing 3

A workflow is a sequence of so-called workflow components. We can also define properties (just like in ant). The workflow engine is a dependency injection container, so it is responsible for creating the components and wiring them together. Therefore we have to specify the concrete class that should be instantiated as the component (it has to posses a default constructor). This is done using the class attribute. Alternatively we can refer to another workflow description using the file attribute.
In the workflow from Listing 3 we first import a properties file that contains two properties:
model=model.pp gendir=src-gen/
Then we define two components. The first one is the parser. As you can see we refer to another workflow file (.../Parser.oaw). It has been generated by xText and includes the parser and the check component. So we don't have to care about the internal details, we just have to use the provided black box (we call such a black box a cartridge). The cartridge needs a number of parameters. The first parameter passed to the parser cartridge is called metaModel. It has a class attribute itself, so the workflow engine takes care of creating a respective object and injecting the nested property (metaModelFile) through a respective setter method (setMetaModelFile(java.lang.String)). The other two parameters for the parser cartridge are modelFile and outputSlot. The modelFile points to the text file that contains the model we want to parse.
The second one requires slightly more explanation. Components communicate with each other using so called slots. In our example the parser reads a model, creates an object graph and stores it in a slot called m. Slots are a lot like variables. So when subsequently the xPand generator is invoked we access the model in the slot using the slot name as a variable in the expression that starts the generation process: gen::C::struct FOREACH m.messages.
Running the Workflow
There are different ways to execute a workflow. If you use Eclipse, the simplest way is probably to use the launch short cut provided by the openArchitectureWare plug-ins. Alternatively you can use the good old command line or an ant-task included in oAW. A suitable Maven2 target is on it's way.
Conclusion
We have seen only about 20% of the features openArchitectureWare provides for generator development. We don't want to show all the advanced features such as AOP, polymorphic template calls, model-to-model transformations or the recipe framework here. Instead our goal was to show how to start with a few concepts and build a simple generator so you can learn and use more and more features as your generator evolves. We strongly advocate a bottom-up, iterative, hands-on approach to Model-Driven Software Development. MDSD is not about drawing boxes and lines and generating boilerplate code to compensate for arguably weak programming models (such as the one provided by EJB 2). And it's also not just about defining constraints for "non-architects" so they don't need to think anymore about what kind of code they write. Generators are just one of many weapons against complexity - albeit a powerful one! So if you think about abstractions be sure to have generator development tools like openArchitectureWare in your toolbox.
References
[1] - "The Pragmatic Programmer: From Journeyman to Master" by Andy Hunt and David Thomas, Addison-Wesley 1999
[2] - "Model-Driven Software Development: Technology, Engineering, Management" by Tom Stahl and Markus Voelter, Wiley 2006
[3] - openArchitectureWare generator framework, http://www.eclipse.org/gmt/oaw
[4] - OCL 2.0 Specification, http://www.omg.org/docs/ptc/05-06-06.pdf
About the Authors
Sven Efftinge is an independent software architect and technology partner of the German company Itemis. His main interests are model-driven software development, Eclipse and the Spring framework. Sven is a main developer of the openArchitectureWare 4 framework.
Markus Volter is an internationally renowned expert on model-driven software development, software architecture and middleware. He has been involved with many challenging projects in domains as diverse as finance, web, automotive embedded and scientific applications. Markus is a regular speaker at international software conferences and has written a number of books on the relevant topics.
Arno Haase works as an independent software architect, working both in the actual construction of software systems and in consulting companies on their strategic alignment. He has been working in the industry for fifteen years, participating in numerous projects in a variety of roles. During the last years, he has specialized in introducing model-driven approaches both at the project and the organization level. He is a regular speaker at software conferences and the author of numerous patterns and magazine articles, many of them on model-driven software development, as well as a book.
Bernd Kolb focuses on model-driven software development and eclipse technologies. As a consultant he worked in different domains from tooling for automotive embedded systems to enterprise Java applications. He is a regular speaker at conferences and has written a number of articles as well as co-authored a book.






