ACID is Good. Take it in Short Doses
This article is about why ACID is good for you, why ACID doesn't work in long doses, why you shouldn't give up and what concepts, models and technologies you can take in longer doses.
Some of you may remember the Five Minute University by Father Guido Sarducci of Saturday Night Live fame. In five minutes, Sarducci teaches you everything you actually remember from college after five years. His topics include Economics (supply and demand), Spanish (¿Cómo está Usted? Muy bien), Theology (Where is God? God is everywhere) and Business (Buy something, sell it for more).
If Sarducci’s Five Minute University were to cover Transaction Theory, he would probably teach you “ACID is good. Take it in short doses.” Congratulations if you still remember that after five years out of college. As with all of Sarducci’s five-minute phrases there is no explanation behind the five-minute phrases. This article is about why ACID is good for you, why ACID doesn’t work in long doses, why you shouldn’t give up and what concepts, models and technologies you can take in longer doses.
ACID is good
Do you remember when you first learned to write a program? Perhaps it was in high school. Looking back, remember how simple it was? You didn’t worry about the effects of your program failing. You didn’t worry about the effects of multiple users and multiple threads of control accessing shared data. You simply wrote your single threaded algorithms on transient data. Maybe you accessed files, but you probably didn’t worry too much about it.
If you develop challenging distributed enterprise applications and systems, short ACID transactions are your friends. The ACID properties of transactions enable you to write software without considering the complex environment in which the application runs. ACID transactions bring simple high-school programming to the complex real world. With ACID transactions you can concentrate on the application logic and not on failure detection, recovery and synchronizing access to shared data.
With ACID transactions, your software need not include logic to recover the state of the application should it fail. Instead you simply define transaction boundaries in your application and the system ensures atomicity – the actions taken within the transaction will happen completely, or not at all. If the application fails midstream, the system will recover to the previous state, as if the transaction never took place. If you have ever written an application without transactions that attempted to detect failures and recover from them, you know that logic can get quite complex.
ACID transactions preserve consistency. Assuming there are no bugs in your transaction, the transaction will take the system from one consistent state to another. The good news is that atomicity and isolation make writing a transaction without bugs easier. You focus on getting the application logic correct in the high school programming environment, not in the complex environment.
Consistency is especially important in a web application with dynamic servers. When users navigate a web application, they are viewing snapshots of the server state. If the snapshot is computed within a transaction, the state returned to the user is consistent. For many applications this is extremely important. Otherwise the inconsistent view of the data could be confusing to the user. Many developers have the incorrect perception that you don’t need transactions if all you are doing is reading a database. If you are doing multiple reads and you want them to be consistent, then you need to do them within a transaction.
With ACID transactions, your software need not be a complicated concurrent program in which you explicitly synchronize multiple concurrent activities accessing shared data. The concurrent transactions are isolated from each other. There is concurrency – multiple transactions accessing shared data can run concurrently – it’s just that you do not have to worry about it in your application. The transaction code is written assuming it is the only code accessing the data.
The individual actions of a transaction are scheduled to execute according to some notion of correctness. A schedule is serializable if it has the same effect as running the transactions serially, that is just the way you wrote the code. It is up to the system to produce a correct schedule. If you have ever written a complex multi-threaded program, you know it is hard to get it right, test it and debug it. Serializability is a formally defined property that allows you to avoid concurrent programming.
Many databases and some application servers weaken serializability with their so-called isolation levels. This requires you to reason about using inconsistent data and this is hard. You have to use application knowledge to argue that a transaction reading an inconsistent, possibly to be rolled-back value, doesn’t matter to the correctness of the application. Furthermore, the weaker isolation levels are not the same from one database to another. This makes porting your application very hard. Only until recently have the weaker isolation levels been formally defined. [ALO]
Finally, the effects of transactions are durable, that is when a transaction commits the new state is persistently stored. “Durable” makes for a nice acronym.
Take it in Short Doses
Unfortunately, ACID transactions do not work effectively over a long period of time. Do not expect things to work if your transactions last more than even a few seconds. Forget putting transaction boundaries around units of work that last minutes, hours, days, months or years. This eliminates defining transactions that do a lot of computation or ones that include user input. Users are finicky – they drink coffee, go on vacation and die. You cannot expect them to commit their work in a timely manner.
This is the so-called “long transaction problem”. No one has found a solution for it after many years of research. The basic problem is achieving isolation – the “I” in “ACID”. There are no known concurrency control algorithms that will operate over a long period of time. Concurrency control algorithms for ensuring serializability come in two flavors: pessimistic and optimistic.
Pessimistic concurrency control algorithms achieve serializable transactions by locking shared resources. In two-phase locking, a transaction obtains its locks in phase 1 and holds on to them until it completes. Competing transactions waiting for the same shared resource block until the first transaction completes. If the transaction holds the shared resource for a long time, little work is accomplished concurrently because the competing transactions are blocked for a long time.
Optimistic concurrency control algorithms let transactions access shared resources and then validate the resulting schedule at commit time. If the schedule violates serializability, the transaction is rolled back. This works when the transactions are short – a small amount of work is rolled back. If the transaction is long-lived, the system appears to be humming along but after doing all of that work, it starts rolling back the transactions.
Don’t Give Up
Just because you cannot achieve ACID properties over a long period of time, do not throw up your hands and forget long-lived activities. [MP] Applications do operate over long periods of time and without considering what happens over the long period of time, you may end up with unwanted processing, inconsistent data or garbage in your database.
Consider a simple Web application collecting user data through a series of forms. To be more specific, assume the application lets a user plan a trip and each form is related to one piece of the trip. The first reserves a car, the second reserves a hotel and the third reserves a flight. In order to achieve atomicity, we might be tempted to start a transaction before the trip planning exercise begins and to commit the transaction after the car, the hotel and the flight have been reserved. But since a user is involved, the activity is long-lived and we cannot make it an ACID transaction.
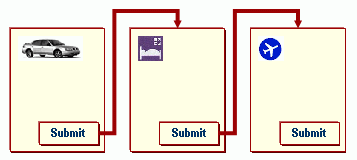
We should still model this long-lived activity and consider what happens over the long period of time. At each form the user enters data and clicks on the submit button. After submitting the first form, the server reserves the hotel. After submitting the second form, the server reserves the car and after submitting the third form, the server reserves the flight. Each one of these steps is a single, short ACID transaction. But what happens if the user completes the first two steps and not the third? If we don’t consider the long-lived activity, the application could end up reserving the car and the hotel but not the flight.
Over the years, several techniques have been proposed for managing long-lived activities. One of the first is called a Saga. [GGKKS] Sagas require you to define compensating transactions. A compensating transaction compensates for the effects of a transaction. For example, a compensating transaction for reserving a hotel room would be a transaction that cancels the reservation.
Given a long-lived activity as a sequence of short ACID transactions T1, T2 … Tn and compensating transactions C1, C2 … Cn, the Saga ensures that either T1, T2 … Tn complete or T1, T2 … Tj, Cj, Cj-1 … C1 complete. In other words, either the long-lived activity completes or compensating transactions are run in reverse order from the last successful short ACID transaction.
Consider the long-lived activity:
Begin reserveCar(); reserveHotel(); reserveFlight(); End
Assume that after running reserveHotel(), the long-lived activity “rolls back.” The Saga compensates by running cancelHotel() and cancelCar(). The sequence of short transactions actually run would be:
reserveCar(); reserveHotel(); cancelHotel(); cancelCar();
The Saga is approximating atomicity over a long period of time. Note however, it is not providing the isolation property. In the example, if a transaction reserves the last car, a second transaction can observe that fact and conclude there are no cars available. But if later we compensate for the first transaction by canceling the reservation, the second transaction has observed an inconsistent state. If they were isolated, the second transaction would never have observed the status of the rental car agency until the first long-lived activity completed. But remember we cannot achieve isolation over a long period of time. Just as we live with this in the real world, our computer applications must as well.
Sagas define a simple model approximating atomicity over a long period of time. But when we consider what we need in a real application, we want to generalize Sagas. For example, if the reserveHotel() operation failed because there were no more rooms left in the hotel, we may want to try to reserve a room in a different hotel. Rather than rolling back the long-lived activity, we want to explore a different path. When we generalize Sagas to support more general computations we end up with workflow.
Unfortunately, today’s application servers do not have any built in support for long-lived activities. You should model what happens in your application over a long period of time but you will need to implement all of it. For example, if Sagas fit your application, you would need to implement the infrastructure necessary to run compensating transactions.
Fortunately, this lack of support may change in the future. Standards have been defined to support long-lived activities and extended transaction models. The Web Services world is adopting compensating transactions. CORBA has defined the Activity Service and the Java world has JSR 95: J2EETM Activity Service [JSR95] for Extended Transactions.
J2EE Activity Service
As you’ve seen, ACID transactions aren’t sufficient for everything and Sagas are one possible solution. However, there are a range of extended transaction models, each typically suited to a specific set of use cases. What this means is that one size doesn’t fit all and as usual it is necessary to “use the right tool for the right job”. A good architect, whether working in the world with bricks and mortar or databases and entity beans, needs to know about all of the tools at his disposal.
Therefore, rather than provide support for a single model, such as Sagas, JSR 95 defines an infrastructure to support a wide range of extended transaction models. The architecture is based on the insight that the various extended transaction models can be supported by providing a general purpose event signaling mechanism that can be programmed to enable activities (application specific units of computations) to coordinate each other in a manner prescribed by the extended transaction model under consideration.
An activity is actually a fairly abstract entity, whose precise nature needs to be defined by applications or users of the service. Whatever work an activity does, the result of a completed activity is its outcome, which can be used to determine subsequent flow of control to other activities. Activities can run over long periods of time and can be suspended and resumed later, similarly to the Java Transaction API (JTA). Activities can also be transactional, using JTA transactions, though they don’t have to use the native application server transactions at all.
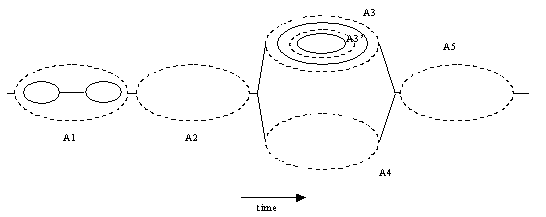
If you look at the example activity structure, the solid ellipses represent JTA transaction boundaries, whereas the dotted ellipses are activity boundaries. Activity A1 uses two top-level transactions during its execution, whereas A2 uses none. Additionally, transactional activity A3 has another transactional activity, A3’ nested within it. The J2EE Activity Service is responsible for distributing both the activity and transaction contexts between execution environments in order that the hierarchy can be fully distributed.
Containers and high level services
The HLS is the embodiment of an extended transaction service in the J2EE Activity Service architecture. It’s a service-provider component that plugs into the application server and offers to applications, service-specific interfaces that are mediated by the application server through interactions between the HLS and the Activity Service. The most important components in the HLS are the Action, Signal and SignalSet: it’s these interfaces and classes that are at the heart of the pluggable coordination nature of the Activity Service.
At its heart, the J2EE Activity Service is really about supporting the coordination and control of these activities through a pluggable protocol layer: the coordinator intelligence (for example, whether it runs a typical two-phase commit protocol or a three-phase commit protocol) can be written by a third party to be plugged into the J2EE Activity Service infrastructure.
Associated with each activity is a coordinator that can coordinate the execution of constituent activities or participants. Demarcation messages (javax.activity.Signals) are sent between activities by the coordinator. In order to allow the architecture to be extensible, Signals are used to encode arbitrary protocol messages that flow between activities.
public class Signal
{
public org.omg.CORBA.Any getExtendedAny ();
public java.io.Serializable getExtendedValue ();
public java.lang.String getName ();
public java.lang.String getSignalSetName ();
};
The org.omg.CORBA.Any is CORBA’s way of allowing arbitrary object types to be communicated between clients and services and is needed for interoperability with the original OMG work. Obviously at some point it’s necessary to be able to decode the Signal payload, and the getName methods helps with this.
Now a coordination protocol that only sends a single type of message is not the normal case (e.g., two-phase commit can have 4 types of message flowing from the coordinator to the participant: prepare, commit, rollback commit_one_phase). So, the Activity Service lets messages associated with a specific coordination model be grouped into a javax.activity.SignalSet. The SignalSet is also the place where the pluggable coordinator intelligence goes, but we’ll come onto that in a moment, after we finish gluing together activities.
To receive a Signal from one activity, you would register a participant (Action) with that activity’s coordinator. (It’s like registering an XAResource with a JTA transaction.) Although Actions are registered with the coordinator, they are associated with a specific SignalSet, so that any specific Action will receive all messages generated by a SignalSet. The Action interface is fairly generic, as you might expect.
public interface Action
{
public javax.activity.Outcome processSignal(Signal sig) throws ActionErrorException;
}
Signals can be used to infer a flow of control during the execution of an application. For example, the termination of one activity may initiate the start/restart of other activities in a workflow-like environment.
public class Outcome
{
public org.omg.CORBA.Any getExtendedAny ();
public java.io.Serializable getExtendedValue ();
public java.lang.String getName ();
}
One of the keys to the extensibility of this framework is the SignalSet, whose behavior is peculiar to the kind of extended transaction. This is the entity that generates Signals that are sent to participants by the coordinator and processes the results returned. As a result, the coordinator is a fairly lightweight entity, having delegated most of its responsibilities to the SignalSet.
public interface SignalSet
{
public java.lang.String getSignalSetName ();
public Signal getSignal ();
public Outcome getOutcome () throws SignalSetActiveException;
public CoordinationInformation setResponse (Outcome response)
throws SignalSetInactiveException;
public void setCompletionStatus (int completionStatus, int status);
public int getCompletionStatus () throws SignalSetActiveException;
};
The activity coordinator interacts with the SignalSet to obtain the Signal to send to registered Actions. A SignalSet may generate a different sequence of Signals depending upon the state of the activity (e.g., rollback versus commit). The setCompletionStatus method tells the SignalSet what state the activity is in before it starts to generate signals.
The coordinator can then start calling the getSignal method to get the Signal to send to each participant. The coordinator sends each Signal to every registered participant and passes the results (the Outcomes) back to the SignalSet via the setResponse method. This method returns a CoordinationInformation instance which the coordinator uses to determine the flow of the Signals.
With the exception of some predefined Signals and SignalSets, the majority of Signals and SignalSets will be defined and provided by the higher-level applications that make use of this Activity Service framework. Predefined SignalSets include a Synchronization protocol (similar to the JTA one) and a Lifetime protocol that allows activities to be informed when other activities start or end.
Leveraging the Activity Service for the Trip Planning Activity
We’ve already mentioned that Sagas are one means whereby acidity may be relaxed: any work performed by a committed transaction can be undone later if required, by a compensation transaction. Obviously managing these compensation transactions is an issue if you had to do it by hand. We’ll now show how the J2EE Activity Service can be leveraged instead.
Take a look at the sequence of transactions shown below; the dotted ellipse is the controlling activity (Saga “manager”) and the solid ellipses are transactions (C for reserveCar, H for reserveHotel and F for reserveFlight). Each transaction has a corresponding compensation transaction denoted by !C, for example. What we want to do is ensure that if the overall activity decides it can complete successfully (car, hotel and flight have been obtained), then nothing happens. If, however, it needs to cancel, each of the compensation transactions executes in the reverse order.
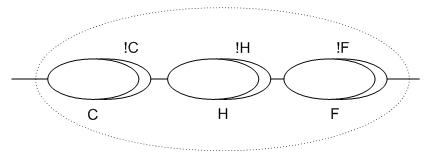
In order to support this scheme within the Activity Service, we first assume that C, H and F execute within their own activity, which has a CompletionSignalSet supporting the Failure (equivalent to roll back) and Propagate (successful completion, but later compensation may be required) Signals. Associated with these activities will be a CompensationAction participant, whose job it is to ensure that the compensation transaction is propagated to the enclosing activity.
For the enclosing activity, we’ll have a SagaSignalSet, which has Signals for Success (no compensation) and Failure (do compensation). It will also ensure that each compensation transaction is executed in the right order (the Activity Service API enables an ordering to be placed on participants when the coordination protocol fires).
So, whenever a transaction begins, a CompensationAction is registered with the enclosing activity. Assuming the transaction commits successfully, the CompletionSignalSet will propagate the CompensationAction to the parent activity and ensure that it is placed in the right order of compensations to be executed.
If at any point a transaction rolls back, the CompletionSignalSet is responsible for ensuring that the enclosing activity must fail, triggering any remaining compensation transactions.
Assuming we manage to get the taxi, hotel and flight, the enclosing activity can terminate successfully and the CompensationActions will be ignored: there’s no work for them to do.
Conclusions
We have discussed why ACID is good, why ACID does not work in long doses, why you should not give up and what concepts, models and technologies you can take in longer doses. We used the simple example of planning a trip to illustrate a long-lived activity. We focused on the simple concept of a Saga as one way of approaching the trip planning activity. But when a Saga is extended, we end up with more generalized workflow models.
We next turned to forthcoming infrastructure to support activities. In particular, we focused on the J2EE Activity Service as defined by JSR-95. We look forward to support for activities in application servers.
Finally, we described how to implement our trip planning activity as a Saga with the J2EE Activity Service. The Activity Service is a more general mechanism than that. Other trip planning behaviors besides atomicity can be achieved using the Activity Service. We leave that as an exercise for you.
References
| [ALO] | Atul Adya, Barbara Liskov, and Patrick O'Neil. “Generalized Isolation Level Definitions.” In Proceedings of the IEEE International Conference on Data Engineering, March 2000. |
| [GGKKS] | Hector Garcia-Molina, Dieter Gawlick, Johannes Klein, Karl Kleissner, Kenneth Salem: "Modeling Long-Running Activities as Nested Sagas," in Database Engineering, Vol. 14, No. 1, March, 1991. |
| [JSR95] | “J2EE Activity Service for Extended Transactions”, http://www.jcp.org/en/jsr/detail?id=95 |
| [LMP] | Mark Little, Jon Maron and Greg Pavlik, Java Transaction Processing: Design and Implementation. Prentice Hall, July 2004. |
| [MP] | Bruce Martin and Claus Pedersen. "Long-lived Concurrent Activities." In Distributed Object Management, edited by Ozsu, Dayal and Valduriez, published by Morgan Kaufmann. |
Author Bios
Mark Little
Before Arjuna Technologies, Mark was a Distinguished Engineer/Architect within HP Arjuna Labs, where he lead the HP-TS and HP-WST teams, developing J2EE and Web services transactions products respectively. Mark is one of the primary authors of the OMG Activity Service specification and is on the expert group for the same work in J2EE (JSR 95). He is on the OTS Revision Task Force and the OASIS BTP and OASIS WS-CAF technical committees. Mark has published extensively in the Web Services Journal, Java Developers Journal and other journals and magazines.
Bruce Martin
Bruce Martin is a Middleware Maven at the Middleware Company. For the past few years, Bruce has been writing, teaching and consulting about J2EE and distributed object technologies. Bruce's recent endeavors have included The Middleware Company's TORPEDO initiative. Bruce created The Middleware Company's popular Architect's Course and has given it to several hundred software architects. Bruce is one of the pioneers of distributed object computing. At Hewlett Packard Laboratories, he designed and implemented an interface definition language that became the basis for HP's original CORBA submission. At Sun Microsystems, he was one of Sun's CORBA architects and was the primary author of five of the OMG's CORBA Services specifications. Bruce holds a Ph.D. and M.S. in Computer Science from the University of California at San Diego.







